Colors in CSS can be specified by the following methods:
Hexadecimal colors
Hexadecimal colors with transparency
RGB colors
RGBA colors
HSL colors
HSLA colors
Predefined/Cross-browser color names
With the currentcolor keyword
Hexadecimal Colors
A hexadecimal color is specified with: #RRGGBB, where the RR (red), GG (green) and BB (blue) hexadecimal integers specify the components of the color. All values must be between 00 and FF.
For example, the #0000ff value is rendered as blue, because the blue component is set to its highest value (ff) and the others are set to 00.
#p1 {background-color: #ff0000;} /* red */ #p2 {background-color: #00ff00;} /* green */ #p3 {background-color: #0000ff;} /* blue */
Hexadecimal Colors With Transparency
A hexadecimal color is specified with: #RRGGBB. To add transparency, add two additional digits between 00 and FF.
#p1a {background-color: #ff000080;} /* red transparency */ #p2a {background-color: #00ff0080;} /* green transparency */ #p3a {background-color: #0000ff80;} /* blue transparency */
RGB Colors
An RGB color value is specified with the rgb() function, which has the following syntax:
rgb(red, green, blue)
Each parameter (red, green, and blue) defines the intensity of the color and can be an integer between 0 and 255 or a percentage value (from 0% to 100%).
For example, the rgb(0,0,255) value is rendered as blue, because the blue parameter is set to its highest value (255) and the others are set to 0.
Also, the following values define equal color: rgb(0,0,255) and rgb(0%,0%,100%).
#p1 {background-color: rgb(255, 0, 0);} /* red */ #p2 {background-color: rgb(0, 255, 0);} /* green */ #p3 {background-color: rgb(0, 0, 255);} /* blue */
RGBA Colors
RGBA color values are an extension of RGB color values with an alpha channel - which specifies the opacity of the object.
An RGBA color is specified with the rgba() function, which has the following syntax:
rgba(red, green, blue, alpha)
The alpha parameter is a number between 0.0 (fully transparent) and 1.0 (fully opaque).
#p1 {background-color: rgba(255, 0, 0, 0.3);} /* red with opacity */ #p2 {background-color: rgba(0, 255, 0, 0.3);} /* green with opacity */ #p3 {background-color: rgba(0, 0, 255, 0.3);} /* blue with opacity */
HSL Colors
HSL stands for hue, saturation, and lightness - and represents a cylindrical-coordinate representation of colors.
HSLA Colors
HSLA color values are an extension of HSL color values with an alpha channel - which specifies the opacity of the object.
Predefined/Cross-browser Color Names
140 color names are predefined in the HTML and CSS color specification.
The currentcolor keyword refers to the value of the color property of an element.
#myDIV { color: blue; /* Blue text color */ border: 10px solid currentcolor; /* Blue border color */ }
Color Schemes
Achromatic Color Schemes
Monochromatic Color Schemes. Monochromatic schemes use different tones from the same angle on the color wheel (the same hue).
Analogous Color Schemes. Analogous color schemes are created by using colors that are next to each other on the color wheel.
Complementary Color Schemes. Complementary schemes are created by combining colors from opposite sides of the color wheel.
Triadic. Triadic schemes are made up of hues equally spaced around color wheel.
Compound (aka Split Complementary) Color Scheme. Compound schemes are almost the same as complementary schemes. Instead of using colors that are opposites, it uses colors on both sides of the opposite hue.
Note: If an element is taller than the element containing it, and it is floated, it will overflow outside of its container. You can use the “clearfix“ hack to fix this. We can add overflow: auto; to the containing element to fix this problem
Vertical Align
Vertically center a div
Vertically center a div using flexbox in the container
Method 1: using align-items: center
align-items: the direction is across with flex-direction.
display:flex; flex-direction:row; /* by default*/ align-items:center;
Method 2: using justify-content: center
justify-content: the direction is the same with flex-direction.
<divid="myDiv">this is multiple lines. this is multiple lines. this is multiple lines. this is multiple lines. this is multiple lines. this is multiple lines. this is multiple lines. </div>
Inline elements in a block element auto wrapping lines until decrease to the block minimal width:
min-width: {fixed_value}
Break Word
word-break: normal; // newline for words
word-break: break-all; // newline for characters
word-break: keep-all; // don’t newline
word-break: break-word; // newline for words, if a single word over the block width then newline for character. Deprecated. Using word-break: normal and overflow-wrap: anywhere replace word-break: break-word.
Common CSS
first-of-type and first-child
xxx:first-of-type: match the first of selector occur from a parent.
xxx:nth-of-type(1)
xxx:last-of-type
xxx:nth-last-of-type(1)
xxx:first-child : match when the first of child of a parent is the selector.
xxx:nth-child(1)
<divclass="column"> <divclass="row">I am .row:first-of-child.</div> <divclass="row">this is a lines. </div> <divclass="row">this is a lines. </div> </div> <divclass="column"> <p>I am p:first-of-child</p> <divclass="row">I am .row:first-of-type not .row:first-of-child.</div> <divclass="row">this is a lines. </div> <divclass="row">this is a lines. </div> </div>
SELECT* FROM information_schema.processlist WHEREuser<>'system user'and COMMAND !='Sleep'and info like'%SELECT%' orderby `time` desc;
Id `User` Host db Command `Time` State Info
Id: thread ID.
db: database name.
Command: Query, Sleep(the session is idle).
Time: the time in seconds that the thread has been in its current state. For a replica SQL thread, the value is the number of seconds between the timestamp of the last replicated event and the real time of the replica host.
Info: the statement the thread is executing, or NULL if it is executing no statement.
Kill Threads By Thread ID
Kill a Particular Thread
KILL {processlist_id};
get kill all your MySQL queries
SELECT GROUP_CONCAT(CONCAT('KILL ',id,';') SEPARATOR ' ') FROM information_schema.processlist WHEREuser<>'system user'and COMMAND !='Sleep'and info like'%SELECT%';
KILL 1; KILL 2;
SELECT CONCAT('KILL ',id,';') AS kill_list FROM information_schema.processlist WHEREuser<>'system user'and COMMAND !='Sleep'and info like'%SELECT%';
Not determined by your operating system display language.
Not determined by your browser display language.
Not determined by the HTTP header Accept-Language.
The web page language for display is determined by the preferred language of your browser. The preferred language list of your browser is the same as your operating system display language or browser display language. But you can set to add your custom preferred language and move it to the top of the list.
Chrome
Chrome settings –> Advanced –> Languages –> Order languages based on your preference –> Add languages –> Move your preferred language for displaying to the top.
Firefox
Options –> General –> Language and Appearance –> Language –> Choose your preferred language for displaying pages –> Choose –> Add your language –> Move your preferred language for displaying to the top.
微信公众平台的接口调用可以在任何支持 HTTP 请求的地方请求并得到返回结果。但“获取access_token 接口”的请求的客户端 IP 需要 IP 白名单中,才能成功返回。然而,调用其它公众平台接口需要 access_token 作为参数,近似相当于没有在 IP 白名单内的客户端请求无法调用微信公众平台接口。不在 IP白名单的客户端的请求结果如下:
This post we are going to talk about NIO and NIO.2 in Java. The NIO was introduced in Java 5. The NIO is missing several features, which were subsequently provided by NIO.2.
Introduction
Input and output (I/O) facilities are fundamental parts of operating systems along with computer languages and their libraries.
Java initial suite of I/O APIs and related architecture are known as classic I/O. Because modern operating systems feature newer I/O paradigms, which class I/O doesn’t support, new I/O (NIO) was introduced as part of JDK 1.4 to support them. Because lack of time, Some other NIO features being deferred to JDK 5 and JDK 7.
Classic I/O
JDK 1.0 introduced I/O facilities for accessing the file system, accessing file content randomly, and streaming byte-oriented data between sources and destinations in a sequential manner.
NIO
Modern operating systems offer sophisticated I/O services (such as readiness selection) for improving I/O performance and simplifying I/O. Java Specification Request (JSR) 51 was created to address these capabilities.
JSR 51’s description indicates that it provides APIs for scalable I/O, fast buffered binary and character I/O, regular expressions, and charset conversion. Collectively, these APIs are known as NIO. JDK 1.4 implemented NIO in terms of the following APIs:
Buffers
Channels
Selectors
Regular expressions
Charsets
Buffers
Buffers are the foundation for NIO operations. Essentially, NIO is all about moving data into and out of buffers.
The process of a classic read operation like the following steps. The operating system issues a command to the disk controller to read a block of bytes from a disk into operating system buffer. Once this operation complete, the operating system copies the buffer contents to the buffer specified by the process when it issued a read() operation.
These are some inefficiency in classic I/O. Copying bytes from the operating system buffer to the process buffer isn’t very efficient. It would be more performance to have the DMA controller copy directly to the process buffer, but there are two problems with this approach:
The DMA controller typically cannot communicate directly with the user space in which the JVM process runs.
Block-oriented device such as a DMA controller work with fixed-size data blocks.
Because of these problems, the operating system acts as an intermediary, tearing apart and recombining data as if switches between the JVM process and the DMA controller.
The data assembly/disassembly tasks can be made more efficient by letting the JVM process pass a list of buffer addresses to the operating system in a single call. The operating system then fills or drains these buffers in sequence, scattering data to multiple buffers during a reading or gathering data from several buffers during a write operation. This scatter/gather activity reduces the number of system calls.
JDK 1.4’s java.nio.Buffer class abstracts the concept of a JVM process buffer.
Channels
Forcing a CPU to perform I/O tasks and wait for I/O completions is wasteful of this resource. Performance can be improved by offloading these tasks to DMA controllers so that the processor can get on with other work.
A channel serves as conduit for communicating (via the operating system) with a DMA controller to efficiently drain byte buffers to or fill byte buffers form a disk. JDK 1.4’s java.nio.channels.Channel interface, its subinterfaces, and various classes implement the channel architecture.
Selectors
I/O is classified as block-oriented or stream-oriented. Reading from or writing to a file is an example of block-oriented I/O. In contrast, reading from the keyboard or writing to a network connection is an example of stream-oriented I/O.
Stream I/O is often slower than block I/O. Many operating systems allow streams to be configured to operate in nonblocking mode in which a thread continually checks available input without blocking when no input is available. The thread can handle incoming data or perform other tasks until data arrives.
This “polling for available input” activity can be wasteful, especially when the thread needs to monitor many input streams. Modern operating systems can perform this checking efficiently, which is known as readiness selection, and which is often built on top of nonblocking mode. The operating system monitors a collection of streams and returns an indication to the thread of which streams are ready to perform I/O. As a result, a single thread can multiplex many active streams via common code and makes it possible.
JDK 1.4 supports readiness selection by providing selectors, which are instances of the java.nio.channels.Selector class that can examine one or more channels and determine which channels are ready for reading or writing.
NIO.2
JSR 51 specifies that NIO would introduce an improved file system interface, and to support asynchronous I/O and complete socket channel functionality. However, lack of time prevented these features from being included. JSR 203 was subsequently created to address these features, which introduced in JDK 7.
Improved File System Interface
The legacy File class suffers from various problems. For example, the renameTo() method doesn’t work consistently across operating systems. The new file system interface fixes these and other problems.
Asynchronous I/O
Nonblocking mode improves performance by preventing a thread that performs a read or write operation on a channel from blocking until input is available or output has been fully written. However, it doesn’t let an application determine if it can perform an operation without actually performing the operation. Nonblocking mode can’t separate code that checks for stream readiness form the data-processing code without making your code significantly complicated.
Asynchronous I/O overcomes this problem by letting the thread initiate the operation and immediately proceed to other work. The thread specifies some kind of callback function that is invoked when the operation finishes.
Completion of Socket Channel Functionality
JDK 1.4 added the DatagramChannel, ServerSocketChannel, and SocketChannel classes to the java.nio.channels package. However, lack of time prevented these classes form supporting binding and option configuration. Also, channel-based multicast datagrams were not supported. JDK 7 added binding support and option configuration to the aforementioned classes. Also, it introduced a new java.nio.channels.MulticastChannel interface.
Buffers
NIO is based on buffers, whose contents are sent to or received from I/O services via channels. This section introduces to NIO’s buffer classes.
Buffer Classes
A buffer is an object that stores a fixed amount of data to be sent to or received from an I/O service. It sits between an application and a channel that writes the buffered data to the service or reads the data from the service and deposits it into the buffer.
Buffers are not safe for use by multiple concurrent threads. If a buffer is to be used by more than one thread then access to the buffer should be controlled by appropriate synchronization.
Buffers have four basic properties:
Capacity. It is the number of elements it contains.
Limit. It is the index of the first element that should not be read or written.
Position. It is the index of the next element to be read or written. A buffer’s position is never negative and is never greater than its limit.
Mark. It’s the index to which its position will be reset when the reset method is invoked.
boolean hasRemaining(). Tells whether there are any elements between the current position and the limit.
int remaining(). Returns the number of elements between the current position and the limit.
Set Buffer’s Property
Buffer limit(int newLimit). Sets this buffer’s limit.
Buffer position(int newPosition). Sets this buffer’s position.
Buffer mark(). Sets this buffer’s mark at its position.
Buffer reset(). Resets this buffer’s position to the previously-marked position.
Clearing, flipping, and rewinding
Buffer clear(). Clears this buffer. It makes a buffer ready for a new sequence of channel-read or relative put operations. The position is set to zero, the limit is set to the capacity, and the mark is discard. Invoke this method before using a sequence of channel-read or put operation to fill this buffer. For example, buf.clear(); in.read(buf);
Buffer flip(). Flips this buffer. It makes a buffer ready for a new sequence of channel-write or relative get operations. The limit is set to the current position, the position is set to zero. If the mark is defined then it is discarded. After a sequence of channel-read or put operations, invoke this method to prepare for a sequence of channel-write or relative get operations. For example, buf.put(magic); in.read(buf); buf.flip(); out.write(buf);. This method is often used in conjunction with the compact method when transferring data from one place to another.
Buffer rewind(). Rewinds this buffer. It makes a buffer ready for re-reading the data that it already contains. The position is set to zero and the mark is discarded. Invoke this method before a sequence of channel-write or get operations, assuming that the limit has already bean set appropriately. For example, out.write(buf); buf.rewind(); buf.get(array);
Buffers in Depth
Buffer Creation
ByteBuffer and the other primitive-type buffer classes declare various class methods for creating a buffer of that type.
Methods for creating ByteBuffer instances:
ByteBuffer allocate(int capacity)
ByteBuffer allocateDirect(int capacity)
ByteBuffer wrap(byte[] array)
ByteBuffer wrap(byte[] array, int offset, int length)
These methods show two ways to create a byte buffer: create the ByteBuffer object and allocate an internal array that stores capacity bytes or create the ByteBuffer object and use the specified array to store these bytes. For example:
Buffers can manage data stored in other buffers. View buffers are create a buffer that manages another buffer’s data. View buffers share the same internal array. Each buffer has its own position, limit and mark.
buffer.flip() equals buffer.limit(buffer.position()).position(0). A example flipping buffer:
buffer.put(s); buffer.flip(); while (buffer.hasRemaining()){ System.out.print(buffer.get()); } buffer.clear();
Compact Buffers
The compact() method moves unwritten buffer data to the beginning of the buffer so that the next read() method call appends read data to the buffer’s data instead of overwriting that data. Do this in case of a partial write.
buf.clear(); while (in.read(buf) != -1){ buf.flip(); out.write(buf); buf.compact(); }
Byte Ordering
Nonbyte primitive types except for Boolean are composed of several bytes. Each value of one of these multibyte types is stored in a sequence of contiguous memory locations. However, the order of these bytes can differ from operating system to operating system.
For example, consider 32-bit long integer 0x10203040. This value’s four bytes could be stored in memory (from low address to high address) as 10, 20, 30, 40; this arrangement is known as big endian order (the most-significant byte, the “big” end, is stored at the lowest address). Alternatively, these bytes could be stored as 40, 30, 20, 10; this arrangement is known as little endian order (the least-significant byte, the “little” end, is stored at the lowest address).
Java provides the java.nio.ByteOrder class to help you deal with byte-order issues when writing/reading multibyte value to/from a multibyte buffer. ByteOrder declares a ByteOrder nativeOrder() method that returns the operating system’s byte order as a ByteOrder instance. This instance is one of ByteOrder’s BIG_ENDIAN and LITTLE_ENDIAN constants.
static ByteOrder BIG_ENDIAN
static ByteOrder LITTLE_ENDIAN
ByteOrder nativeOrder()
ByteBuffer its default byte order is always big endian, even when the underlying operating system’s byte order is little endian. Because Java’s default byte order is also big endian, which lets classfiles and serialized objects store data consistently across Java virtual machines.
Big endian default can impact performance on little endian operating systems, ByteBuffer also declares a ByteBuffer order(ByteOrder bo) method to change the byte buffer’s byte order.
Although it may seem unusual to change the byte order of a byte buffer, this method is useful because ByteBuffer also declares several convenience methods for writing and reading multibyte values, such as ByteBuffer putInt(int value) and int getInt(). These convenience methods write these values according to the byte buffer’s current byte order.
Direct Byte Buffers
Operating systems can directly access the address space of a process. For example, an operating system could directly access a JVM process’s address space to perform a data transfer operation based on a byte array. However, a JVM might not store the array of bytes contiguously or its garbage collector might move the byte array to another location. Because of these limitations, direct byte buffer were created.
A direct byte buffer is a byte buffer that interacts with channels and native code to perform I/O. The direct byte buffer attempts to store byte elements in a memory area that a channel uses to perform direct (raw) access via native code that tells the operating system to drain or fill the memory area directly.
Direct byte buffers are the most efficient means performing I/O on the JVM. Although you can also pass non-direct byte buffers to channels, a performance problem might arise because non-direct byte buffers are not always to serve as the target of native I/O operations.
Although direct byte buffers are optimal for I/O, a direct byte buffer can be expensive to create because memory extraneous to the JVM’s heap will need to be allocated by the operating system, and setting up/tearing down this memory might take longer than when the buffer way located within the heap.
After your code is working and should you want to experiment with performance optimization, you can easily obtain a direct byte buffer by invoking ByteBuffer’s allocateDirect() method.
Channels
Channels partner with buffers to achieve high-performance I/O.
A Channel is an object that represents an open connection to a hardware device, a file, a network socket, an application component, or another entity that’s capable of performing writes, reads, and other I/O operations. Channels efficiently transfer data between byte buffers and operating system-based I/O service sources or destinations.
All channels are instances of classes that ultimately implement the java.nio.channels.Channel interface. The Chennel declares the following methods:
void close()
boolean isOpen()
To support I/O, channel is extended by the WritableByteChannel and ReadableByteChannel interface.
WritableByteChannel declares an abstract int write(ByteBuffer buffer) method that writes a sequence of bytes from buffer to the current channel.
ReadableByteChannel declares an abstract int read(ByteBuffer buffer) method that reads bytes from current channel into buffer.
A channel whose class implements only WritableByteChannel or ReadableByteChannel is unidirectional.
InterruptibleChannel interface describes a channel that can be asynchronous closed and interrupted.
NIO’s designers chose to shut down a channel when a blocked thread is interrupted because they couldn’t find a way to reliably handle interrupted I/O operations in the same manner across operating systems. The only way to guarantee deterministic behavior was to shut down the channel.
Obtain a channel
There are two ways to obtain a channel:
The java.nio.channels package provides a Channels utility class that offers two methods for obtaining channels from streams.
For example, obtain channels from standard I/O streams:
ReadableByteChannelsrc= Channels.newChannel(System.in); WritableByteChanneldest= Channels.newChannel(System.out); ByteBufferbuffer= ByteBuffer.allocateDirect(2048); while (src.read(buffer) != -1){ buffer.flip(); dest.write(buffer); buffer.compact(); } buffer.flip(); while (buffer.hasRemaining()){ dest.write(buffer); }
Channels in Depth
Scatter/Gather I/O
Channels provide the ability to perform a single I/O operation across multiple buffers. This capability is known as scatter/gather I/O (and is also known as vectored I/O).
In the context of a write operation, the contents of several buffers are gathered in sequence and then sent through the channel to a destination. In the context of a read operation, the contents of a channel are scattered to multiple buffers in sequence.
Modern operating systems provide APIs that support vectored I/O to eliminate (or at least reduce) system calls or buffer copies, and hence improve performance.
Java Provides the java.nio.channels.ScatteringByteChannel interface to support scattering and GatheringByteChannel interface to support gathering.
ScattheringByteChannel offers the following methods:
long read(ByteBuffer[] buffers, int offset, int length)
long read(ByteBuffer[] buffers)
GatheringByteChannel offers the following methods:
long write(ByteBuffer[] buffers, int offset, int length)
long write(ByteBuffer[] buffers)
File Channels
RandomAccessFile, FileInputStream, and FileOutputStream provide getChannel() method for returning a file channel instance, which describes an open connection to a file.
The abstract java.nio.channels.FileChannel class describes a file channel. This class implements the InterruptibleChannel, ByteChannel, GatheringByteChannel, and ScatteringByteChannel interfaces.
Unlike buffers, which are not thread-safe, file channels are thread-safe.
A file channel maintains a current position into the file, which FileChannel lets you obtain and change.
Methods of FileChannel:
void force(boolean metadata)
long position()
FileChannel position(long newPosition)
int read(ByteBuffer buffer)
int read(ByteBuffer dst, long position)
long size()
FileChannel truncate(long size)
int write(ByteBuffer buffer)
int write(ByteBuffer src, long position)
FileChannel objects support the concept of a current file position, which determines the location where the next data item will be read from or written to.
The ability to lock all or part of a file was an important but missing feature from Java until Java 1.4 arrived. This capability lets a JVM process prevent other processes form accessing all or part of a file until it’s finished with the entire file or part of the file.
Although an entire file can be locked, it’s often desirable to lock a smaller region. For example, a database management system might lock individual table rows.
Locks that are associated with files are known as file locks. Each file lock starts at a certain byte position in the file and has a specific length (in bytes) from this position.
There are two kinds of file locks: exclusive and shared.
There are some important for file locking:
When an operating system doesn’t support shared locks, a shared lock request is quietly promoted to a request for an exclusive lock.
Locks are applied on a per-file basis. The are not applied on a per-thread or per-channel basis.
FileChannel declares four methods for obtaining exclusive and shared locks:
FileLock lock()
FileLock lock(long position, long size, boolean shared)
FileLock tryLock()
FileLock tryLock(long position, long size, boolean shared)
A FileLock instance is associated with a FileChannel instance but the file lock represented by the FileLock instance associates with the underlying file and not with the file channel. Without care, you can run into conflicts (and possibly even a deadlock) when you don’t release a file lock after you’re finished using it. The following code shows the FileLock usage:
FileLocklock= FileChannel.lock(); try { // interact with the file channel } catch (IOException ioe){ // handle the exception } finally { lock.release(); }
Mapping Files into Memory
FileChannel declares a map() method that lets you create a virtual memory mapping between a region of an open file and a java.nio.MappedByteBuffer instance that wraps itself around this region. This mapping mechanism offers an efficient way to access a file because no time-consuming system calls are needed to perform I/O. The map method is:
MappedByteBuffer map(FileChannel.MapMode mode, long position, long size)
FileChannel.MapMode enumerated type:
READ_ONLY
READ_WRITE
PRIVATE
Changes made to the resulting buffer will eventually be propagated to the file. They might not be made visible to other programs that have mapped the same file.
The specified mapping mode is constrained by the invoking FileChannel object’s access permissions. For example, if the file channel was opened as a read-only channel, and if you request READ_WRITE mode, map() will throw NonWritableChannelException.
Invoke MappedByteBuffer‘s isReadOnly() method to determine whether or not you can modify the mapped file.
The position and size parameters define the start and extent of the mapped region.
There is no unmap() method. Once a mapping is established, it remains until the MappedByteBuffer object is garbage collected (or the application exits).
The following code shows A MappedByteBuffer example:
Socket declares a SocketChannel getChannel() method for returning a socket channel instance, which describes an open connection to a socket. Unlike sockets, socket channels are selectable and can function in nonblocking mode. These capabilities enhance the scalability and flexibility of large applications.
Socket channels are describes by the java.nio.channels package’s abstract ServerSocketChannel, SocketChannel, and DatagramChannel classes. Each class ultimately extends SelectableChannle and InterruptibleChannel, making socket channels selectable and interruptible.
SelecableChannel offers the following methods to enable blocking or nonblocking:
static ServerSocketChannel open(). Attempt to open a server-socket channel, which is initially unbound; it must be bound to a specific address via one of its peer socket’s bind() methods before connections can be accepted.
ServerSocket socket()
SocketChannel accept(). Accept the connection made this channel’s socket. If this channel is nonblocking, it immediately returns null when there are no pending connections or returns a socket channel that represents the connection. Otherwise, when the channel is blocking, it blocks.
SocketChannelsc= SocketChannel.open(); sc.connect(newInetSocketAddress("localhost", 9999)); while (!sc.finishConnect()){ System.out.println("waiting to finish connection"); } ByteBufferbuffer= ByteBuffer.allocate(200); buffer.asCharBuffer().put("hello at " + newDate()); // send sc.write(buffer); // receive while (sc.read(buffer) >= 0){ buffer.flip(); while (buffer.hasRemaining()){ System.out.print((char) buffer.get()); } buffer.clear(); } sc.close();
Pipes
Pipe describes a pair of channels that implement a unidirectional pipe, which is a conduit for passing data in one direction between two entities, such as two file channels or two socket channels. Pipe is analogous to the java.io.PipedInputStream and PiepedOutputStream.
Pipe declares nested SourceChannel and SinkChannel classes that serve as readable and writable byte channels, respectively. Pipe also declares the following methods:
static Pipe open()
SourceChannel source()
SinkChannel sink()
Pipe can be used to pass data within the same JVM. Pipes are ideal in producer/consumer scenarios because of encapsulation: you can use the same code to write data to files, sockets, or pipes depending on the kind of channel presented to the pipe.
The following code shows a producer/consumer example:
Nonblocking mode doesn’t let an application determine if it can perform an operation without actually performing the operation.
The operating system is instructed to observe a group of streams and return some indication of which streams are ready to perform a specific operation (such as read). This capability lets a thread multiplex a potentially huge number of active streams by using the readiness information provided by the operating system.
Selectors let you achieve readiness selection in a Java context.
What is Selectors
A selector is an object created form a subclass of the abstract java.nio.channels.Selector class. The selector maintains a set of channels that it examines to determine which channels are ready for reading, writing, completing a connection sequence, accepting another connection, or some combination of these tasks. The actual work is delegated to the operating system via POSIX select() or similar system call.
How selectors work
Selectors are used with selectable channels, which are objects whose classes ultimately inherit from the abstract java.nio.channels.SelectableChannel class, which describes a channel that can be multiplexed by a selector.
One or more previously created selectable channels are registered with a selector. Each registration returns an instance of a subclass of the abstract SelectionKey class, which is a token signifying the relationship between one channel and the selector. This key keeps track of two sets of operations: interest set and ready set. The interest set identifies that will be tested for readiness the next time one of the selector’s selection methods is invoked. The ready set identifies the key’s channel has been found to be ready.
How to use selectors
Selector‘s methods
abstract void close()
abstract boolean isOpen()
abstract Set<SelectionKey> keys(). Returns this selector’s key set.
static Selector open(). Open a selector.
abstract SelectorProvider provider()
abstract int select(). Returns the number of channels that have become ready for I/O operations since the last time it was called.
abstract int select(long timeout). Set timeout for selector’s selection operation.
abstract Set<SelectionKey> selectedKeys(). Returns this selector’s selected-key set.
abstract int selectNow(). It’s a nonblocking version of select().
abstract Selector wakeup(). If another thread is currently blocked in an invocation of the select() or select(long) methods then that invocation will return immediately.
SelectableChannel‘s methods
SelectionKey register(Selector sel, int ops)
SelectionKey register(Selector sel, int ops, Object att). The third parameter att (a non-null object) is known as an attachment and is a convenient way of recognizing a given channel or attaching additional information to the channel. It’s stored in the SelectionKey instance returned from this method.
SelectionKey
int-based constants to ops
OP_ACCEPT. Operation-set bit for socket-accept opertions.
OP_CONNECT. Operation-set bit for socket-connect operations.
OP_READ. Operation-set bit for read operations.
OP_WRITE. Operation-set bit for write operations.
abstract SelectableChannel channel()
An application typically operations
Performs a selection operation.
Obtains the selected keys followed by an iterator over the selected keys.
Iterates over these keys and performs channel operations (read, write).
A selection operation is performed by invoking one of Selector’s selection methods. It doesn’t return until at least one channel is selected, until this selector’s wakeup() method is invoked, or until the current thread is interrupted, whichever comes first.
A key presents a relationship between a selectable channel and a selector. This relationship can be terminated by invoking SelectionKey’s cancel() method.
When you’re finished with a selector, call Selector’s close() method. If a thread is currently blocked in one of this selector’s selection methods, it’s interrupted as if by invoking the selector’s wakeup() method. Any uncancelled keys still associated with this selector are invalidated, their channels are deregistered, and any other resources associated with this selector are released.
The following code shows a example of selector usage:
// get channels ServerSocketChannelchannel= ServerSocketChannel.open(); channel.configureBlocking(false); // register channels to the selector Selectorselector= Selector.open(); SelectionKeykey= channel.register(selector, SelectionKey.OP_ACCEPT | SelectionKey.OP_READ | SelectionKey.OP_WRITE); // selection operation while(true){ intnumReadyChannels= selector.select(); if (numReadyChannels == 0){ contine; } Set<SelectionKey> selectedKeys = selector.selectedKeys(); Iterator<SelectionKey> keyIterator = selectedKeys.iterator(); while(keyIterator.hasNext){ SelectionKeykey= keyIterator.next(); if (key.isAcceptable()){ ServerSocketChannelserver= (ServerSocketChannel) key.channel(); SocketChannelclient= server.accept(); if (client == null){ continue; } client.configureBlocking(false); client.register(selector, SelectionKey.OP_READ); } elseif (key.isReadable()){ SocketChannelclient= (SocketChannel) key.channel(); // Perform work on the socket channel... } elseif (key.isWritable()){ SocketChannelclient= (SocketChannel) key.channel(); // Perform work on the socket channel... } } }
Asynchronous I/O
NIO provides multiplexed I/O to facilitate the creation of highly scalable servers. Client code registers a socket channel with a selector to be notified when the channel is ready to start I/O.
NIO.2 provides asynchronous I/O, which lets client code initiate an I/O operation and subsequently notifies the client when then operation is complete. Like multiplexed I/O, asynchronous I/O is also commonly used to facilitate the creation of highly scalable servers.
The main concepts of asynchronous I/O are: asynchronous I/O overview, asynchronous file channels, asynchronous socket channels, and asynchronous channel groups.
Asynchronous I/O Overview
The java.nio.channels.AsynchronousChannel interface describes an asynchronous channel, which is a channel that supports asynchronous I/O operation (reads, writes, and so on).
An asynchronous I/O operation is initiated by calling a method that returns a future or requires a completion handler argument, Like
Future<V> operation(...). The Future methods may be called to check if the I/O operation has completed.
void opertion(... A attachment, CompletionHandler<V, ? super A> handler). The attachment is used for a stateless CompletionHandler object consume the result of many I/O operations. The handler is invoked to consume the result of the I/O operation when it completes or fails.
CompletionHandler declares the following methods to consume the result of an operation when it completes successfully, and to learn why the operation failed and take appropriate action:
void complted(V result, A attachment)
void failed(Throwable t, A attachment)
After an asynchronous I/O operation called, the method returns immediately. You then call Future methods or provide code in the CompletionHandler implementation to learn more about the I/O operation status and/or process the I/O operation’s results.
The java.nio.channels.AsynchronousByteChannel interface extends AsynchronousChannel. It offers the following four methods:
Future<Integer> read(ByteBuffer dst)
<A> void read(ByteBuffer dst, A attachment, CompletionHandler<Integer,? super A> handler)
Future<Integer> write(ByteBuffer src)
<A> void write(ByteBuffer src, A attachment, CompletionHandler<Integer,? super A> handler)
Asynchronous File Channels
The abstract java.nio.channels.AsynchronousFileChannel class describes an asynchronous channel for reading, writing, and manipulating a file.
This channel is created when a file is opened by invoking one of AsynchronousFileChannel’s open() methods.
The file contains a variable-length sequence of bytes that can be read and written, and whose current size can be queried.
Files are read and written by calling AsynchronousFileChannel’s read() and write() methods. One pair returns a Future and the other pair receives a CompletionHandler as an argument.
An asynchronous file channel doesn’t have a current position within the file. Instead, the file position is passed as an argument to each read() and write() method that initiates asynchronous operations.
AsynchronousFileChannel’s methods
asynchronous I/O operations
Future<FileLock> lock()
<A> void lock(A attachment, CompletionHandler<FileLock, ? super A> handler)
abstract Future<Integer> read(ByteBuffer dst, long position)
abstract <A> void read(ByteBuffer dst, long position, A attachment, CompletionHandler<Integer, ? super A> handler)
abstract Future<Integer> write(ByteBuffer src, long position)
abstract <A> void write(ByteBuffer src, long position, A attachment, CompletionHandler<Integer, ? super A> handler)
The abstract java.nio.channels.AsynchronousServerSocketChannel class describes an asynchronous channel for stream-oriented listening sockets. Its counterpart channel for connecting sockets is described by the abstract java.nio.channels.AsynchronousSocketChannel class.
The abstract java.nio.channels.AsynchronousChannelGroup class describes a grouping of asynchronous channels for the purpose of resource sharing. A group has an associated thread pool to which tasks are submitted, to handle I/O events and to dispatch to completion handlers that consume the results of asynchronous operations performed on the group’s channels.
AsynchronousServerSocketChannel and AsyynchronousSocketChannel belong to gourps. When you create an asynchronous socket channel via the no-argument open() method, the channel is bound to the default group.
AsynchronousFileChannel don’t belong to groups. However, they are associated with a thread pool which tasks are submitted, to handle I/O events and to dispatch to completion handlers that consume the results of I/O operations on the channel.
You can configure the default gourp by initializing the following system properties at JVM startup:
java.nio.channels.DefaultThreadPool.threadFactory
java.nio.channels.DefaultThreadPool.initialSize
You can define your own channel group. It gives you more control over the threads that are used to service the I/O operations. Furthermore, it provides the mechanisms to shut down threads and to await termination. You can use AsynchronousChannelGroup’s methods to create your own channel group:
static AsynchronousChannelGroup withCachedThreadPool(ExecutorService executor, int initialSize)
// After the operation has begun, the channel group is used to control the shutdown. if (!group.isShutdown()) { // After the group is shut down, no more channels can be bound to it. group.shutdown(); } if (!group.isTerminated()) { // Forcibly shut down the group. The channel is closed and the // accept operation aborts. group.shutdownNow(); } // The group should be able to terminate; wait for 10 seconds maximum. group.awaitTermination(10, TimeUnit.SECONDS);
Summary
NIO is nonblocking and selectable, and it provides non-blocking IO and multiplexed I/O to facilitate the creation of highly scalable servers
NIO channels read() and write() operations are nonblocking.
Channels read and write operations are work with buffers. For example, write a buffer data to a channel (to a device), read data from a channel (from a device) into a buffer.
NIO channels are selectable it can be managed with a selector. A selector maintains a set of channels that it examines to determine which channels are ready for reading, writing, completing a connection sequence, accepting another connection, or some combination of these tasks. The actual work is delegated to the operating system via POSIX select() or similar system call.
NIO provides non-blocking IO and multiplex I/O, but it still needs to check the channels’ status with a loop. The NIO.2’s asynchronous IO can get notifies when the operation is complete. Like multiplexed I/O, asynchronous I/O is also commonly used to facilitate the creation of highly scalable servers.
All of IO, non-blocking IO, asynchronous IO are supported by the operating system.
In this post, we are going to diving into the Spring framework in deep. The main content of this post is to analyze IoC implementation in the source code of the Spring framework.
Basics
Basic Concepts
Bean and BeanDefinition
In Spring, the objects that form the backbone of your application and that are managed by the Spring IoC container are called beans. A bean is an object that is instantiated, assembled, and otherwise managed by a Spring IoC container.
A Spring IoC container manages one or more beans. These beans are created with the configuration metadata that you supply to the container, for example, in the form of XML <bean/> definitions.
Within the container itself, these bean definitions are represented as BeanDefinition objects.
BeanWrapper
BeanWrapper is the central interface of Spring’s low-level JavaBeans infrastructure. Typically not used directly but ranther implicitly via a BeanFactory or a DataBinder. It provides operations to analyze and manipulate standard JavaBeans: get and set property values, get property descriptors, and query the readability/writability of properties.
IoC Containers
IoC container is the implementation of IoC functionality in the Spring framework. The interface org.springframework.context.ApplicationContextrepresents the Spring IoC container and is responsible for instantiating, configuring, and assembling the aforementioned beans. The container gets its instructions on what objects to instantiate, configure, and assemble by reading configuration metadata. The configuration metadata is represented in XML, Java annotations, or Java code. It allows you to express the objects that compose your application and the rich interdependencies between such objects.
Several implementations of the ApplicationContext interface are supplied out-of-the-box with Spring. In standalone applications it is common to create an instance of ClassPathXmlApplicationContext or FileSystemXmlApplicationContext.
BeanFactory vs ApplicationContext
Spring provides two kinds of IoC container, one is XMLBeanFactory and other is ApplicationContext. The ApplicationContext is a more powerful IoC container than BeanFactory.
Bean Factory
Bean instantiation/wiring
Application Context
Bean instantiation/wiring
Automatic BeanPostProcessor registration
Automatic BeanFactoryPostProcessor registration
Convenient MessageSource access (for i18n)
ApplicationEvent publication
WebApplicationContext vs ApplicationContext
WebApplicationContext interface provides configuration for a web application. This is read-only while the application is running, but may be reloaded if the implementation supports this.
WebApplcationContext extends ApplicationContext. This interface adds a getServletContext() method to the generic ApplicationContext interface, and defines a well-known application attribute name that the root context must be bound to in the bootstrap process.
WebApplicationContext in Spring is web aware ApplicationContext i.e it has Servlet Context information. In single web application there can be multiple WebApplicationContext. That means each DispatcherServlet associated with single WebApplicationContext.
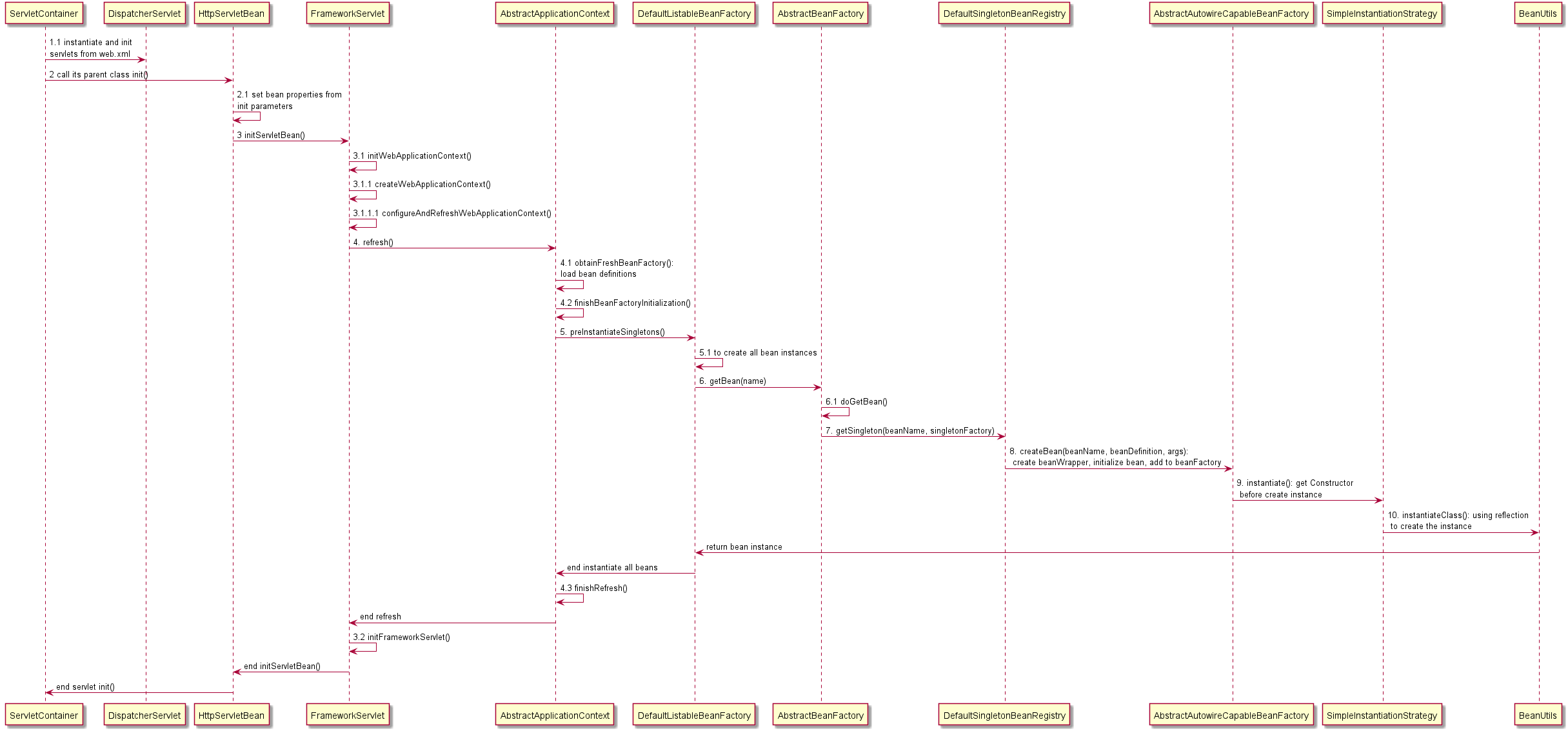
The following figure shows the process of IoC implementation.
Next, We are going to analyze the implementation in the source code of every step.
1 Java web project starting
1.1 instantiate and init servlets from web.xml
When a Java web project running in an application server like Apache Tomcat, the servlet container of the server will load, instantiate, and init Java servlets that be <load-on-startup> from web.xml file.
As this is a startup method, it should destroy already created singletons if it fails, to avoid dangling resources. In other words, after invocation of that method, either all or no singletons at all should be instantiated.
AbstractApplicationContext.java
publicvoidrefresh()throws BeansException, IllegalStateException { //... // 1. Create a BeanFactory instance. Refer to #4.1 ConfigurableListableBeanFactorybeanFactory=this.obtainFreshBeanFactory(); // 2. Configure properties of AbstractApplicationContext, prepare for bean initialization and context refresh this.postProcessBeanFactory(beanFactory); this.invokeBeanFactoryPostProcessors(beanFactory); this.registerBeanPostProcessors(beanFactory); this.initMessageSource(); this.initApplicationEventMulticaster(); this.onRefresh(); this.registerListeners(); // 3. bean initialization. Refer to #4.2 this.finishBeanFactoryInitialization(beanFactory); // 4. context refresh. this.finishRefresh(); // ... }
4.1 obtainFreshBeanFactory()
Create a BeanFactory instance in AbstractRefreshableApplicationContext.
AbstractRefreshableApplicationContext.java
protectedfinalvoidrefreshBeanFactory()throws BeansException { //... // 1. Creating a BeanFactory instance. DefaultListableBeanFactorybeanFactory=this.createBeanFactory(); // 2. Set BeanFactory instance's properties beanFactory.setSerializationId(this.getId()); this.customizeBeanFactory(beanFactory); // 3. load bean definitions this.loadBeanDefinitions(beanFactory); // 4. assign this new BeanFactory instance to the AbstractRefreshableApplicationContext's field beanFactory synchronized(this.beanFactoryMonitor) { this.beanFactory = beanFactory; } //... }
// 1. check is the bean instance in creation if (sharedInstance != null && args == null) { //... } else { // 2. get and check beanDefinition by beanName RootBeanDefinitionmbd=this.getMergedLocalBeanDefinition(beanName); this.checkMergedBeanDefinition(mbd, beanName, args); // 3. to get different type bean instance: singleton, prototype, and so on. if (mbd.isSingleton()) { // to create singleton bean instance go to #7 sharedInstance = this.getSingleton(beanName, () -> { try { returnthis.createBean(beanName, mbd, args); } catch (BeansException var5) { this.destroySingleton(beanName); throw var5; } }); bean = this.getObjectForBeanInstance(sharedInstance, name, beanName, mbd); } elseif (mbd.isPrototype()) { //... } else{ //... } } }
7 getSingleton(beanName, singletonFactory) in DefaultSingletonBeanRegistry
To get singleton bean instance.
DefaultSingletonBeanRegistry.java
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) { // 1. check conditions and logging //... // 2. to get a singleton bean instance, go to #8 singletonObject = singletonFactory.getObject(); newSingleton = true; // 3. add created singleton bean instance to the bean list if (newSingleton) { this.addSingleton(beanName, singletonObject); } }
protectedvoidaddSingleton(String beanName, Object singletonObject) { synchronized(this.singletonObjects) { // add bean instance to the bean list "singletonObjects" this.singletonObjects.put(beanName, singletonObject); this.singletonFactories.remove(beanName); this.earlySingletonObjects.remove(beanName); this.registeredSingletons.add(beanName); } }
8 createBean(beanName, beanDefinition, args) in AbstractAutowireCapableBeanFactory
To get a bean instance, create a beanWrapper, initialize the bean, add add the bean to the beanFactory.
AbstractAutowireCapableBeanFactory.java
protected Object createBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)throws BeanCreationException { // ... // 1. construct a beanDefinition for use. // ... // 2. try to create bean instance ObjectbeanInstance=this.resolveBeforeInstantiation(beanName, mbdToUse); if (beanInstance != null) { return beanInstance; } // 3. try to create bean instance again if fail to create in first time beanInstance = this.doCreateBean(beanName, mbdToUse, args); return beanInstance; }
protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)throws BeanCreationException { // 1. to construct a beanWrapper and create the bean instance BeanWrapperinstanceWrapper=this.createBeanInstance(beanName, mbd, args); // 2. post processing //... // 3. Add bean to the beanFactory and some bean instances record list this.addSingletonFactory(beanName, () -> { returnthis.getEarlyBeanReference(beanName, mbd, bean); }); // 4. autowired and handle property values this.populateBean(beanName, mbd, instanceWrapper); // 5. initialization bean exposedObject = this.initializeBean(beanName, exposedObject, mbd); // 6. return bean return exposedObject; }
protected BeanWrapper instantiateBean(String beanName, RootBeanDefinition mbd) { // 1. to create the bean instance ObjectbeanInstance=this.getInstantiationStrategy().instantiate(mbd, beanName, this);
// 2. create the BeanWrapper by bean instance BeanWrapperbw=newBeanWrapperImpl(beanInstance); this.initBeanWrapper(bw); return bw; }
9 instantiate() in SimpleInstantiationStrategy
Get the Constructor of the bean class and to get the bean instance.
SimpleInstantiationStrategy.java
public Object instantiate(RootBeanDefinition bd, @Nullable String beanName, BeanFactory owner) { // 1. get the Constructor of the bean class ConstructorconstructorToUse= (Constructor)bd.resolvedConstructorOrFactoryMethod; Class<?> clazz = bd.getBeanClass(); constructorToUse = (Constructor)AccessController.doPrivileged(() -> { return clazz.getDeclaredConstructor(); }); // 2. to craete bean instance return BeanUtils.instantiateClass(constructorToUse, newObject[0]); }
10 instantiateClass() in BeanUtils
Using reflection to create a instance.
BeanUtils.java
publicstatic <T> T instantiateClass(Constructor<T> ctor, Object... args)throws BeanInstantiationException { //... // Using reflection to create instance return ctor.newInstance(argsWithDefaultValues); }
Conclusion
Spring framework uses the servlet container loads the DispatcherServlet when server startup to trigger the automatic beans instantiation.
The ApplicationContext is responsible for the whole process of beans instantiation. There is a BeanFactory as a field in the ApplicationContext, it is responsible to create bean instances.
The important steps of beans instantiation are: load bean definitions, create and initialize beanFactory, create and initialize bean instances, keep bean records in beanFactory.
Many applications perform well with the default settings of a JVM, but some applications require additional JVM tuning to meet their performance requirement. A well-tuned JVM configurations used for one application may not be well suited for another application. As a result, understanding how to tune a JVM is a necessity.
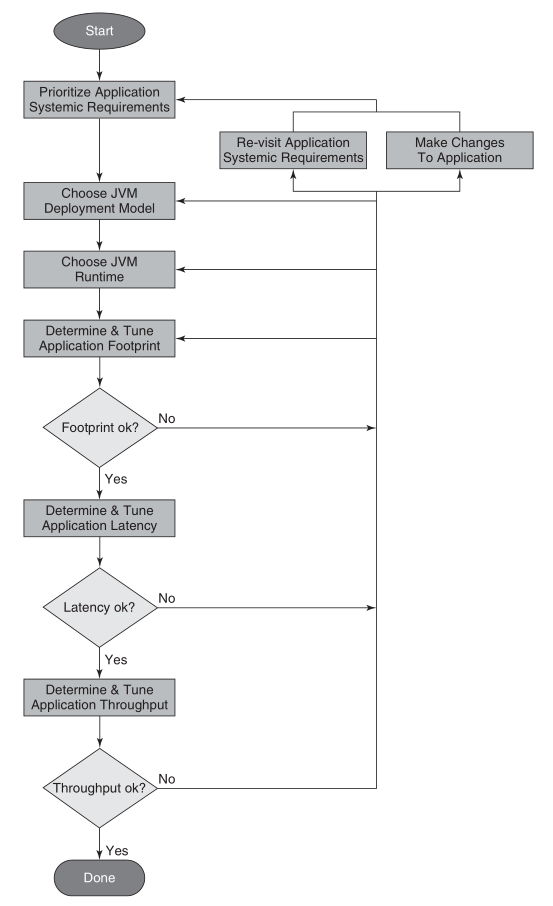
Process of JVM Tuning
The following figure shows the process of JVM tuning.
The first thing of JVM tuning is prioritize application systemic requirements. In contrast to functional requirements, which indicate functionally what an application computes or produces for output, systemic requirements indicate a particular aspect of an application’s such as its throughput, response time, the amount of memory it consumes, startup time, availability, manageability, and so on.
Performance tuning a JVM involves many trade-offs. When you emphasize one systemic requirement, you usually sacrifice something in another. For example, minimizing memory footprint usually comes at the expense of throughput and/or latency. As you improve manageability, you sacrifice some level of availability of the application since running fewer JVMs puts a larger portion of an application at risk should there be an unexpected failure. Therefore, when emphasizing systemic requirements, it is crucial to the tuning process to understand which are most important to the application.
Once you know which systemic requirements are most important, the following steps of tuning process are:
Choose a JVM deployment mode.
Choose a JVM runtime environment.
Tuning the garbage collector to meet your application’s memory footprint, pause time/latency, and throughput requirements.
For some applications and their systemic requirements, it may take several iterations of this process until the application’s stakeholders are satisfied with the application’s performance.
Application Execution Assumptions
An initialization phase where the application initializes important data structures and other necessary artifacts to begin its intended use.
A steady state phase where the application spends most of its time and where the application’s core functionality is executed.
An optional summary phase where an artifact such as a report may be generated, such as that produced by executing a benchmark program just prior to the application ending its execution.
The steady state phase where an application spends most of its time is the phase of most interest.
Testing Infrastructure Requirements
The performance testing environment should be close to the production environment. The better the testing environment replicates the production environment running with a realistic production load, the more accurate and better informed tuning decision will be.
Application Systemic Requirements
There are several application systemic requirements, such as its throughput, response time, the amount of memory it consumes, its availability, its manageability, and so on.
Availability
Availability is a measure of the application being in an operational and usable state. An availability requirement expresses to what extent an application, or portions of an application, are available for use when some component breaks or experiences a failure.
In the context of a Java application, higher availability can be accomplished by running portions of an application across multiple JVMs or by multiple instances of the application in multiple JVMs. One of the trade-offs when emphasizing availability is increased manageability costs.
Manageability
Manageability is a measure of the operational costs associated with running and monitoring the application along with how easy it is configure the application. A manageability requirement expresses the ease with which the system can be managed. Configuration tends to be easier with fewer JVMs, but the application’s availability may be sacrificed.
Throughput
Throughput is a measure of the amount of work that can be performed per unit time. A throughput requirement ignores latency or responsiveness. Usually, increased throughput comes at the expense of either an crease in latency and/or an increase in memory footprint.
Latency and Responsiveness
Latency, or responsiveness, is a measure of the elapsed time between when an application receives a stimulus to do some work and that work is completed. A latency or responsiveness requirement ignores throughput. Usually, increased responsiveness or lower latency, comes at the expense of lower throughput and/or an increase in memory footprint.
Memory Footprint
Memory footprint is a measure of the amount of memory required to run an application at a some level of throughput, some level of latency, and/or some level of availability and manageability. Memory footprint is usually expressed as either the amount of Java heap required to run the application and/or the total amount of memory required to run the application.
Startup Time
Startup time is a measure of the amount of time it takes for an application to initialize. The time it takes to initialize a Java application is dependent on many factors including but not limited to the number of classes loaded, the number of objects that require initialization, how those objects are initialized, and the choice of a HotSpot VM runtime, that is, client or server.
Rank Systemic Requirements
The first step in the tuning process is prioritizing the application’s systemic requirements. Doing so involves getting the major application stakeholders together and agreeing upon the prioritization.
Ranking the systemic requirements in order of importance to the application stakeholders is critical to the tuning process. The most important systemic requirements drive some of the initial decisions.
Choose JVM Deployment Model
There is not necessarily a best JVM deployment model. The most appropriate choice depends on which systemic requirements (manageability, availability, etc.) are most important.
Generally, with JVM deployment models has been the fewer the JVMs the better. With fewer JVMs, there are fewer JVMs to monitor and manage along with less total memory footprint.
Choose JVM Runtime
Choosing a JVM runtime for a Java application is about making a choice between a runtime environment that tends to be better suited for one or another of client and server applications.
There are several runtime environments to consider: client or server runtime, 32-bit or 64-bit JVM, and garbage collectors.
Client or Server Runtime
There are three types of JVM runtime to choose from when using the HotSpot VM: client, server, or tiered.
The client runtime is specialized for rapid startup, small memory footprint, and a JIT compiler with rapid code generation.
The server runtime offers more sophisticated code generation optimizations, which are more desirable in server applications. Many of the optimizations found in the server runtime’s JIT compiler require additional time to gather more information about the behavior of the program and to produce better performing generated code.
The tiered runtime which combines the best of the client and server runtimes, that is, rapid startup time and high performing generated code.
If you do not know which runtime to initially choose, start with the server runtime. If startup time or memory footprint requirements cannot be met and you are using Java 6 Update 25 or later, try the tiered server runtime. If you are not running Java 6 Update 25 or later, or the tiered server runtime is unable to meet your startup time or memory footprint requirement, switch to the client runtime.
32-Bit or b4-Bit JVM
There is a choice between 32-bit and 64-bit JVMs.
The following table provides some guidelines for making an initial decision on whether to start with a 32-bit or 64-bit JVM. Note that client runtimes are not available in 64-bit HotSpot VMs.
Operating System
Java Heap Size
32-Bit or 64-Bit JVM
Windows
Less than 1300 megabytes
32-bit
Windows
Between 1500 megabytes and 32 gigabytes
64-bit with -d64 -XX:+UseCompressedOops command line options
Windows
More than 32 gigabytes
64-bit with -d64 command line option
Linux
Less than 2 gigabytes
32-bit
Linux
Between 2 and 32 gigabytes
64-bit with -d64 -XX:+UseCompressedOops command line options
Linux
More than 32 gigabytes
64-bit with -d64 command line option
Oracle Solaris
Less than 3 gigabytes
32-bit
Oracle Solaris
Between 3 and 32 gigabytes
64-bit with -d64 -XX:+UseCompressedOops command line options
Oracle Solaris
More than 32 gigabytes
64-bit with -d64 command line option
Garbage Collectors
There are several garbage collectors are available in the HotSpot VM: serial, throughput, mostly concurrent, and garbage first.
Since it is possible for applications to meet their pause time requirements with the throughput garbage collector, start with the throughput garbage collector and migrate to the concurrent garbage collector if necessary. If migration to the concurrent garbage collector is required, it will happen later in the tuning process as part of determine and tune application latency step.
The throughput garbage collector is specified by the HotSpot VM command line option -XX:+UseParallelOldGC or -XX:+UseParallelGC. The difference between the two is that the -XX:+UseParallelOldGC is both a multithreaded young generation garbage collector and a multithreaded old generation garbage collector. -XX:+UseParallelGC enables only a multithreaded young generation garbage collector.
GC Tuning Fundamentals
GC tuning fundamentals contain the following content: attributes of garbage collection performance, GC tuning principles, and GC logging. Understanding the important trade-offs among the attributes, the tuning principles, and what information to collect is crucial to JVM tuning.
The Performance Attributes
Throughput.
Latency.
Footprint.
A performance improvement for one of these attributes almost always is at the expense of one or both of the other attributes.
The Principles
There are three fundamental principle to tuning GC:
The minor GC reclamation principle. At each minor garbage collection, maximize the number of objects reclaimed. Adhering to this principle helps reduce the number and frequency of full garbage collections experienced by the application. Full GC typically have the longest duration and as a result are applications not meeting their latency or throughput requirements.
The GC maximize memory principle. The more memory made available to garbage collector, that is, the larger the Java heap space, the better the garbage collector and application perform when it comes to throughput and latency.
The 2 of 3 GC tuning principle. Tune the JVM’s garbage collector for two of the three performance attributes: throughput, latency, and footprint.
Keeping these three principles in mind makes the task of meeting your application’s performance requirements much easier.
Command Line Options and GC Logging
The JVM tuning decisions made utilize metrics observed from monitoring garbage collections. Collecting this information in garbage collection logs is the best approach. This garbage collection statistics gathering must be enabled via HotSpot VM command line options. Enabling GC logging, even in production systems, is a good idea. It has minimal overhead and provides a wealth of information that can be used to correlate application level events with garbage collection or JVM level events.
Several HotSpot VM command line options are of interest for garbage collection logging. The following is the minimal set of recommended command line options to use:
In the first line of GC logging, 46.152 is the number of seconds since the JVM launched.
In the second line, PSYoungGen means a young generation garbage collection. 295648K->32968K(306432K) means the occupancy of the young generation space prior and after to the garbage collection. The value inside the parentheses (306432K) is the size of the young generation space, that is, the total size of eden and the two survivor spaces.
In the third line, 296198K->33518K(1006848K) means the Java heap utilization before and after the garbage collection. The value inside the parentheses (1006848K) is the total size of the Java heap.
In the fourth line, [Times: user=1.83 sys=0.01, real=0.11 secs] provides CPU and elapsed time information. 1.83 seconds of CPU time in user mode, 0.01 seconds of operating system CPU time, 0.11 seconds is the elapsed wall clock time in seconds of the garbage collection. In this example, it took 0.11 seconds to complete the garbage collection.
Determine Memory Footprint
Up to this point in the tuning process, no measurements have been taken. Only some initial choices have been made. This step of tuning process provides a good estimate of the amount of memory or Java heap size required to run the application. The outcome of this step identifies the live data size for the application. The live data size provides input into a good starting point for a Java heap size configuration to run the application.
Live data size is the amount of memory in the Java heap consumed by the set of long-lived objects required to run the application in its steady state. In other words, it is the Java heap occupancy after a full garbage collection while the application is in steady state.
Constraints
The following list helps determine how much physical memory can be made available to the JVM(s):
Will the Java application be deployed in a single JVM on a machine where it is the only application running? If that is the case, then all the physical memory on the machine can be made available to JVM.
Will the Java application be deployed in multiple JVMs on the same machine? or will the machine be shared by other processes or other Java application? If either case applies, then you must decide how much physical memory will be made available to each process and JVM.
In either of the preceding scenarios, some memory must be reserved for the operating system.
HotSpot VM Heap Layout
Before taking some footprint measurements, it is important to have an understanding of the HotSpot VM Java heap layout. The HotSpot VM has three major spaces: young generation, old generation, and permanent generation. The heap data area composes of the young generation and the old generation.
The new objects are allocated in the young generation space. Objects that survive after some number of minor garbage collections are promoted into the old generation space. The permanent generation space holds VM and Java class metadata as well as interned Strings and class static variables.
Following command line options specify the size of area data space:
Heap area
-Xmx specified the maximum size of heap.
-Xms specified the initial size of heap.
Young generation
-XX:NewSize=<n>[g|m|k] specified the initial and minimum size of the young generation space.
-XX:MaxNewSize=<n>[g|m|k] specified the maximum size of the young generation space.
-Xmn<n>[g|m|k] sets the initial, minimum, and maximum size of the young generation space.
Permanent generation
-XX:PermSize=<n>[g|m|k] specified the initial and minimum size of permanent generation space.
-XX:MaxPermSize=<n>[g|m|k] specified the maximum size of permanent space.
If any Java heap size, initial or maximum size, young generation size, or permanent generation size is not specified, the HotSpot VM automatically choose values based on the system configuration it discovers through an adaptive tuning feature called ergonomics.
It is important to understand that a garbage collection occurs when any one of the three spaces, young generation, old generation, or permanent generation, is in a state where it can no longer satisfy an allocation event.
When the young generation space does not have enough available to satisfy a Java object allocation, the HotSpot VM performs a minor GC to free up space. Minor GC tend to be short in duration relative to full GC.
When the old generation space no longer has available space for promoted objects, the HotSpot VM performs a full garbage collection. It actually performs a full garbage collection when it determines there is not enough available space for object promotions from next minor garbage collection.
A full garbage collection also occurs when the permanent generation space does not have enough available space to store additional VM or class metadata.
In a full GC, both old generation, permanent generation and young generation are garbage collected. -XX:-ScavengeBeforeFullGC will disable young generation space garbage collection on full garbage collections.
Heap Size Starting Point
To begin the heap size tuning process, a starting point is needed. The approach may start with a larger Java heap size than is necessary to run the Java application. The purpose of this step is to gather some initial data and further refine the heap size to more reasonable values.
For choose JVM runtime, start with the throughput garbage collector. The throughput garbage collector is specified with the -XX:+UseParallelOldGC command lien option.
If you have a good sense of amount of the Java heap space the Java application will required, you can use that Java heap size as a starting point. If you do not know what Java heap size the Java application will require, you can start with the Java heap size the HotSpot VM automatically chooses.
If you observe OutOfMemoryErrors in the garbage collection logs while attempting to put the application into its steady state, take notice of whether the old generation space ro the permanent generation space is running out of memory. The following example illustrates an OutOfMemoryError occurring as a result of a too small old generation space:
If you observe an OutOfmemoryError in the garbage collection logs, try increasing the Java heap size to 80% to 90% of the physical memory you have available for the JVM.
Keep in mind the limitations of Java heap size based on the hardware platform and whether you are using a 32-bit or 64-bit JVM.
After increasing the Java heap size check the garbage collection logs for OutOfMemoryError. Repeat these steps, increasing the Java heap size at each iteration, until you observe no OutOfMemoryErrors in the garbage collection logs.
Once the application is running in its stead state without experiencing OutOfMemoryErrors, the next step is to calculate the application’s live data size.
Calculate Live Data Size
The live data size is the Java heap size consumed by the set of long-lived objects required to run the application in its steady state. In other words, the live data size is the Java heap occupancy of the old generation space and permanent space after a full garbage collection while the application is running in its steady state.
The live data size for a java application can be collected from the garage collection logs. The live data size provides the following tuning information
An approximation of the amount of old generation Java heap occupancy consumed while running the application in steady state.
An approximation of the amount of permanent generation heap occupancy consumed while running the application in steady state.
To get a good measure of an application’s live data size, it is best to look at the Java heap occupancy after several full garbage collections. Make sure these full garbage collections are occurring while the application is running in its steady state.
If the application is not experiencing full garbage collections, or they are not occurring very frequently, you can induce full garbage collections using the JVM monitoring tools VisualVM or JConsole. To force full garbage collections, monitor the application with VisualVM or JConsole and click the Perform GC button. A command line alternative to force a full garbage collection is use the HotSpot JDK distribution jmap command.
$ jmap -histo:live <process_id>
The JVM process id can be acquired using the JDK’s jps command line.
Initial Heap Space Size Configuration
This section describes how to use live data size calculations to determine an initial Java heap size. It is wise to compute an average of the Java heap occupancy and garbage collection duration of several full garbage collections for your live data size calculation.
The general sizing rules shows below figure.
Space
Command Line Option
Occupancy Factor
Java heap
-Xms and -Xmx
3x to 4x old generation space occupancy after full GC
Permanent Generation or Metaspace
-XX:PermSize -XX:MaxPermSize
1.2x to 1.5x permanent generation space occupancy after full GC
Young Generation or New
-Xmn
1x to 1.5x old generation space occupancy after full garbage collection
Old Generation
Implied from overall Java heap size minus the young generation size
2x to 3x old generation space occupancy after full garbage collection.
Additional Considerations
It is important to know that the Java heap size calculated in the previous section does not represent the full memory footprint of a Java application. A better way to determine a Java application’s total memory use is by monitoring the application with an operating system tool such as prstat on Oracle Solaris, top on Linux, and Task Manager on Windows. The Java heap size may not be the largest contributor to an application’s memory footprint. For example, applications may require additional memory for thread stacks. The larger the number of threads, the more memory consumed in threads stacks. The deeper the method calls executed by the application, the larger the thread stacks. The memory footprint estimate for an application must include any additional memory use.
The Java heap sizes calculated in this step are a starting point. These sizes may be further modified in the remaining steps of the tuning process, depending on the application’s requirements.
Tune Latency/Responsiveness
This step begins by looking at the latency impact of the garbage collector starting with the initial Java heap size established in the last step “Determine memory footprint”.
The following activities are involved in evaluating the garbage collector’s impact on latency:
Measuring minor garbage collection duration.
Measuring minor garbage collection frequency.
Measuring worst case full garbage collection duration.
Measuring worst case full garbage collection frequency.
Measuring garbage collection duration and frequency is crucial to refining the Java heap size configuration. Minor garbage collection duration and frequency measurements drive the refinement of the young generation size. Measuring the worst case full garbage collection duration and frequency drive old generating sizing decisions and the decision of whether to switch from using the throughput garbage collector -XX:+UseParallelOldGC to using the concurrent garbage collector -XX:+UseConcMarkSweepGC.
Inputs
There are several inputs to this step of the tuning process. They are derived from the systemic requirements for the application.
The acceptable average pause time target for the application.
The frequency of minor garbage collection included latencies that are considered acceptable.
The maximum pause time incurred by the application that can be tolerated by the application’s stakeholders.
The frequency of the maximum pause time that is considered acceptable by the application’s stakeholders.
Tune Application Throughput
This is the final step of the turning process. The main input into this step is the application’s throughput performance requirements. An application’s throughput is something measured at the application level, not at the JVM level. Thus, the application must report some kind of throughput metric, or some kind of throughput metric must be derived from the operations it is performing. When the observed application throughput meets or exceeds the throughput requirements, you are finished with the tuning process. If you need additional application throughput to meet the throughput requirements, then you have some additional JVM tuning work to do.
Another important input into this step is the amount of memory that can be made available to the deployed Java application. As the GC maximize Memory Principle says, the more memory that can be made available for the Java heap, the better the performance.
It is possible that the application’s throughput requirements cannot be met. In that case, the application’s throughput requirements must be revisited.
Summary
There are some important summaries are shown below:
You should follow the process of JVM tuning.
Your requirements determine what to tuning. There are many trade-offs, you must determine what are most important requirements.
The main requirements for JVM tuning are memory footprint, latency, and throughput.