Introduction to Kubernetes
Kubernetes (K8s) is an open-source container orchestration platform originally developed by Google and now maintained by the Cloud Native Computing Foundation (CNCF).
It automates the deployment, scaling, and management of containerized applications. Instead of running containers manually, Kubernetes provides a framework to run them reliably and at scale across clusters of machines.
In this post, I will introduce the common concepts of Kubernetes.
What is Kubernetes
Kubernetes is a software system for automating the deployment and management of complex, large-scale application systems composed of computer processes running in containers.
What Kubernetes does
Abstracting away the infrastructure
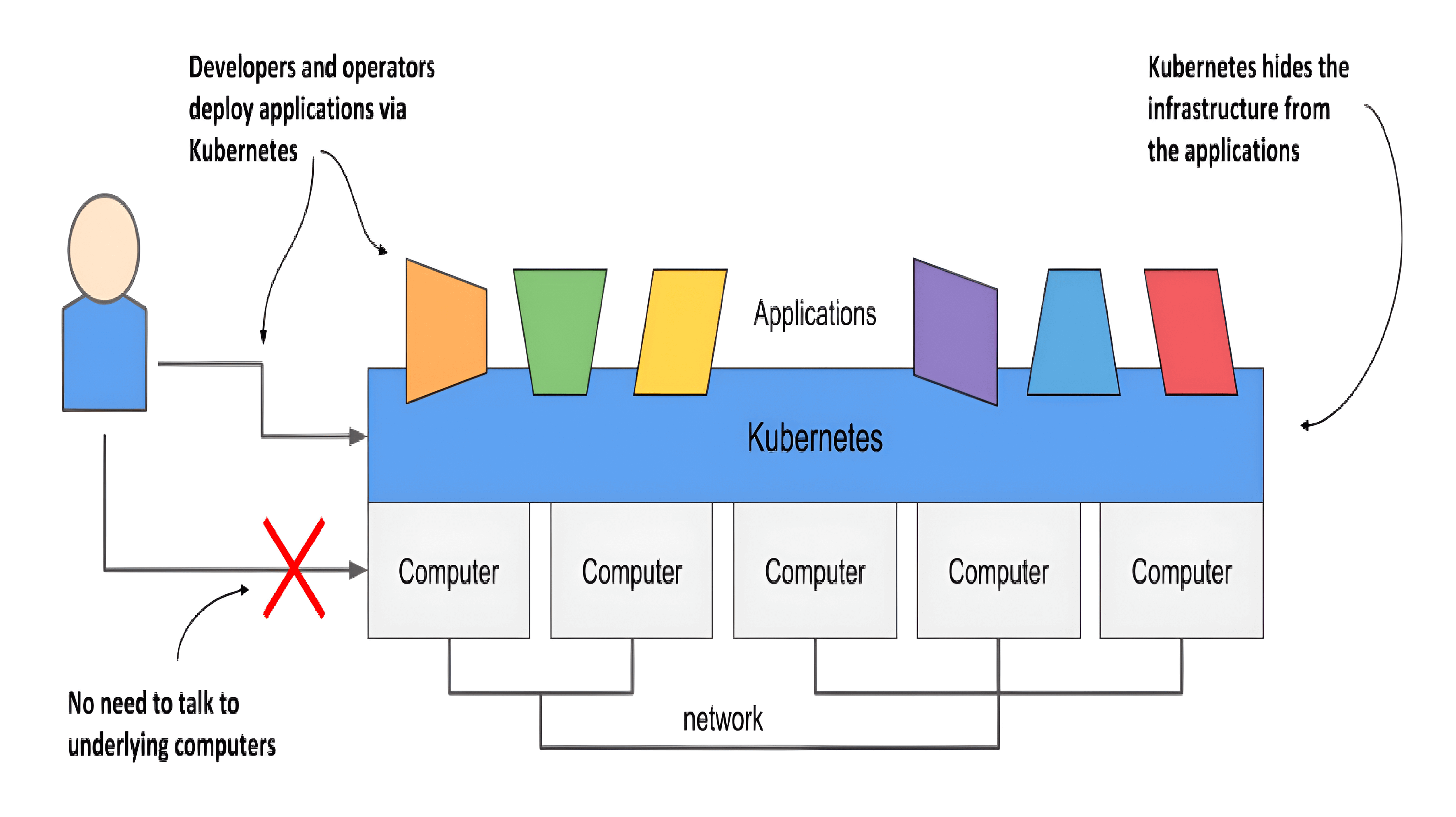
When software developers or operators decide to deploy an application, they do this through Kubernetes instead of deploying the application to individual computers. Kubernetes provides an abstraction layer over the underlying hardware to both users and applications.
As you can see in the following figure, the underlying infrastructure, meaning the computers, the network and other components, is hidden from the applications, making it easier to develop and configure them.
Standardizing how we deploy applications
Because the details of the underlying infrastructure no longer affect the deployment of applications, you deploy applications to your corporate data center in the same way as you do in the cloud. A single manifest that describes the application can be used for local deployment and for deploying on any cloud provider. All differences in the underlying infrastructure are handled by Kubernetes, so you can focus on the application and the business logic it contains.
Deploying applications declaratively
Kubernetes uses a declarative model to define an application. You describe the components that make up your application and Kubernetes turns this description into a running application. It then keeps the application healthy by restarting or recreating parts of it as needed.
Whenever you change the description, Kubernetes will take the necessary steps to reconfigure the running application to match the new description, as shown in the next figure.
Taking on the daily management of applications
As soon as you deploy an application to Kubernetes, it takes over the daily management of the application. If the application fails, Kubernetes will automatically restart it. If the hardware fails or the infrastructure topology changes so that the application needs to be moved to other machines, Kubernetes does this all by itself. The engineers responsible for operating the system can focus on the big picture instead of wasting time on the details.
Why Kubernetes is so popular
Automating the management of microservices
When the system consists of many microservices, automated management is crucial. Kubernetes provides this automation. The features it offers make the task of managing hundreds of microservices almost trivial.
Bridging the dev and ops divide
As a software developer, your primary focus is on implementing the business logic. You don’t want to deal with the details of the underlying servers. Kubernetes hides these details. It allows software developers to focus on implementing business logic.
Standardizing the cloud
All major cloud providers have integrated Kubernetes into their offerings. Customers can now deploy applications to any cloud provider through a standard set of APIs provided by Kubernetes.
If the application is built on the APIs of Kubernetes instead of directly on the proprietary APIs of a specific cloud provider, it can be transferred relatively easily to any other provider.
How Kubernetes works
How Kubernetes transforms a computer cluster
Kubernetes is like an operating system for computer clusters
Just as an operating system supports the basic functions of a computer, such as scheduling processes onto its CPUs and acting as an interface between the application and the computer’s hardware, Kubernetes schedules the components of a distributed application onto individual computers in the underlying computer cluster and acts as an interface between the application and the cluster.
It frees application developers from the need to implement infrastructure-related mechanisms in their applications; instead, they rely on Kubernetes to provide them. This includes things like:
- service discovery - a mechanism that allows applications to find other applications and use the services they provide
- horizontal scaling - replicating your application to adjust to fluctuations in load
- load-balancing - distributing load across all the application replicas
- self-healing - keeping the system healthy by automatically restarting failed applications and moving them to healthy nodes after their nodes fail.
- leader election - a mechanism that decides which instance of the application should be active while the others remain idle but ready to take over if the active instance fails.
By relying on Kubernetes to provide these features, application developers can focus on implementing the core business logic instead of wasting time integrating applications with the infrastructure.
How Kubernetes fits into a computer cluster
You start with a fleet of machines that you divide into two groups: the master and the worker nodes. The master nodes will run the Kubernetes Control Plane, which represents the brain of your system and controls the cluster, while the rest will run your applications - your workloads - and will therefore represent the Workload Plane.
How all cluster nodes become one large deployment area
After Kubernetes is installed on the computers, you no longer need to think about individual computers when deploying applications. Regardless of the number of worker nodes in your cluster, they all become a single space where you deploy your applications. You do this using the Kubernetes API, which is provided by the Kubernetes Control Plane.
The architecture of a Kubernetes cluster
A Kubernetes cluster consists of nodes divided into two groups:
- A set of master nodes that host the Control Plane components, which are the brains of the system, since they control the entire cluster.
- A set of worker nodes that form the Workload Plane, which is where your workloads (or applications) run.
The two planes, and hence the two types of nodes, run different Kubernetes components.
Control Plane components
The components of the Kubernetes Control Plane
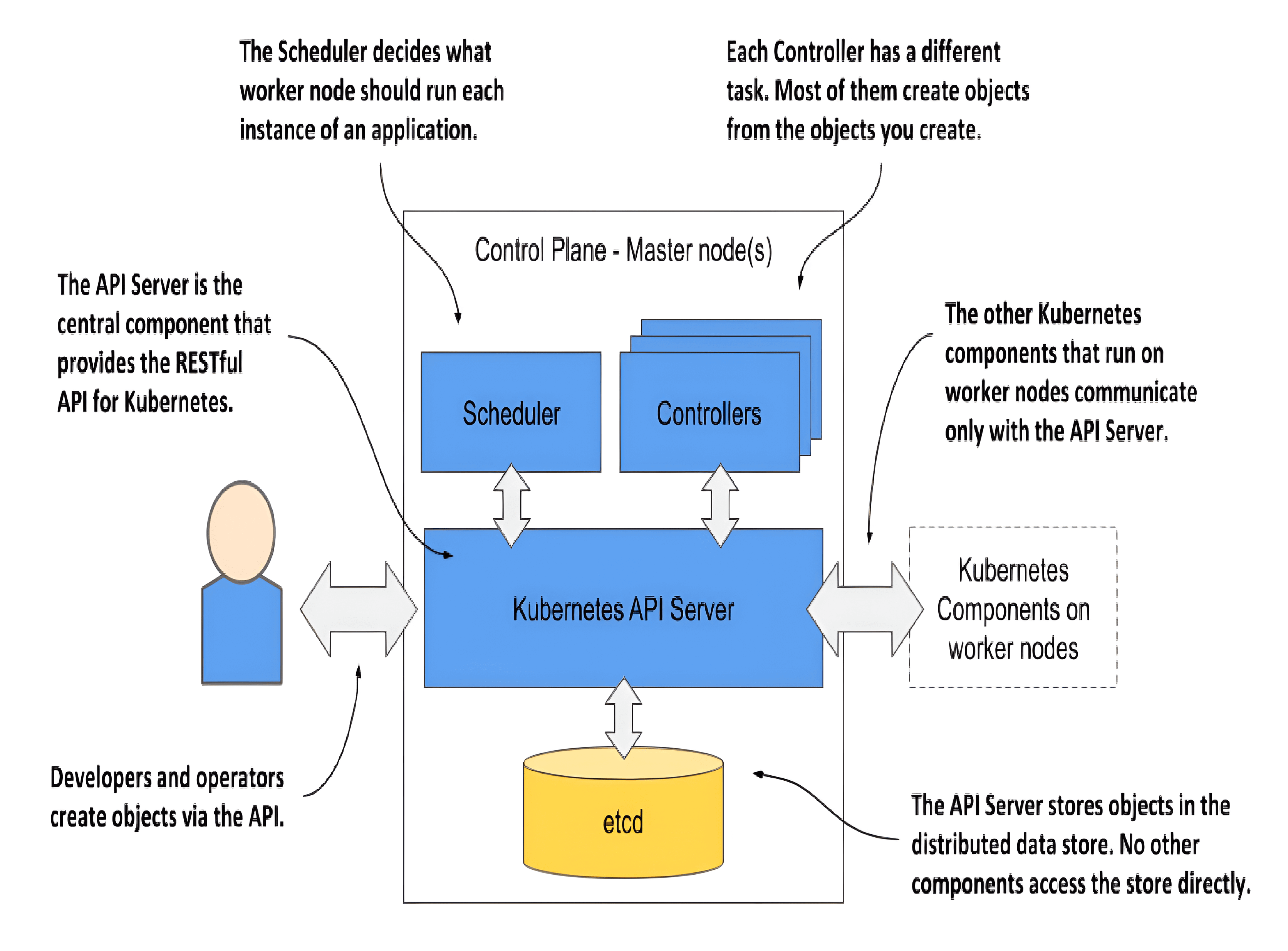
- The Kubernetes API Server exposes the RESTful Kubernetes API. Engineers using the cluster and other Kubernetes components create objects via this API.
- etcd is a distributed, consistent key-value store that serves as the primary backing store for all cluster data in Kubernetes. The etcd distributed datastore persists the objects you create through the API, since the API Server itself is stateless. The Server is the only component that talks to etcd.
- The Scheduler decides on which worker node each application instance should run.
- Controllers bring to life the objects you create through the API. Most of them simply create other objects, but some also communicate with external systems (for example, the cloud provider via its API).
Worker node components
The worker nodes are the computers on which your applications run. They form the cluster’s Workload Plane. In addition to applications, several Kubernetes components also run on these nodes. They perform the task of running, monitoring and providing connectivity between your applications. They are shown in the following figure.
The components of the Kubernetes Workload Plane
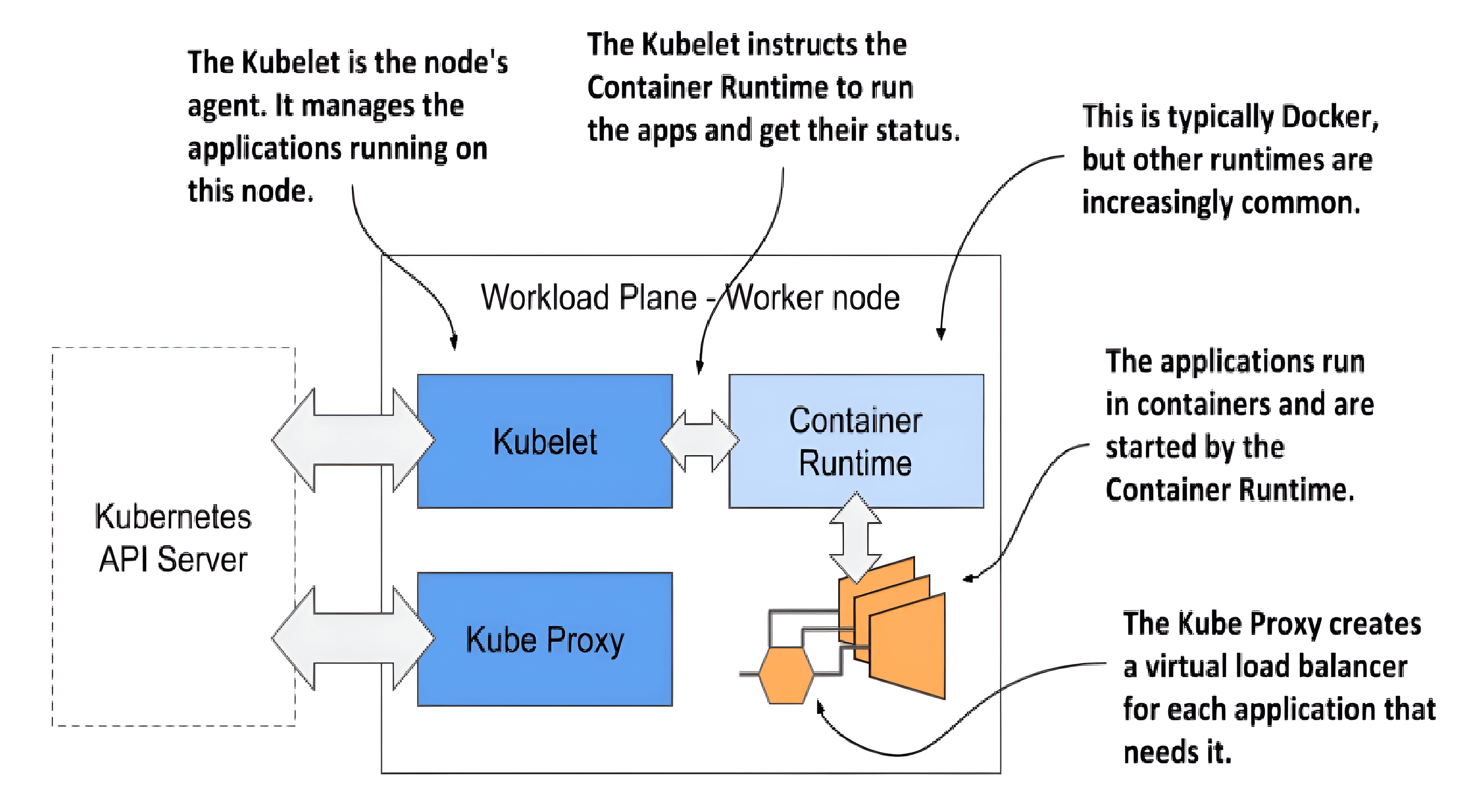
- The Kubelet, an agent that talks to the API server and manages the applications running on its node. It reports the status of these applications and the node via the API.
- The Container Runtime, which can be Docker or any other runtime compatible with Kubernetes. It runs your applications in containers as instructed by the Kubelet.
- The Kubernetes Service Proxy (Kube Proxy) load-balances network traffic between applications. Its name suggests that traffic flows through it, but that’s no longer the case.
Add-on components
Most Kubernetes clusters also contain several other components. This includes a DNS server, network plugins, logging agents and many others. They typically run on the worker nodes but can also be configured to run on the master.
How Kubernetes runs an application
Defining your application
Everything in Kubernetes is represented by an object. You create and retrieve these objects via the Kubernetes API. Your application consists of several types of these objects.
You can define your application through several types of objects. These objects are usually defined in one or more manifest files in either YAML or JSON format.
These actions take place when you deploy the application:
- You submit the application manifest to the Kubernetes API. The API Server writes the objects defined in the manifest to etcd.
- A controller notices the newly created objects and creates several new objects - one for each application instance.
- The Scheduler assigns a node to each instance.
- The Kubelet notices that an instance is assigned to the Kubelet’s node. It runs the application instance via the Container Runtime.
- The Kube Proxy notices that the application instances are ready to accept connections from clients and configures a load balancer for them.
- The Kubelets and the Controllers monitor the system and keep the applications running.
Submitting the application to the API
After you’ve created your YAML or JSON file(s), you submit the file to the API, usually via the Kubernetes command-line tool called kubectl.
Kubectl is pronounced kube-control, but the people in the community prefer to call it kube-cuddle. Some refer to it as kube-C-T-L.
Kubectl splits the file into individual objects and creates each of them by sending an HTTP PUT or POST request to the API, as is usually the case with RESTful APIs. The API Server validates the objects and stores them in the etcd datastore. In addition, it notifies all interested components that these objects have been created.
About the controllers
Most object types have an associated controller. A controller is interested in a particular object type. It waits for the API server to notify it that a new object has been created, and then performs operations to bring that object to life.
About the Scheduler
The scheduler is a special type of controller, whose only task is to schedule application instances onto worker nodes. It selects the best worker node foreach new application instance object and assigns it to the instance - by modifying the object via the API.
About the Kubelet and the Container Runtime
The Kubelet that runs on each worker node is also a type of controller. Its task is to wait for application instances to be assigned to the node on which it is located and run the application. This is done by instructing the Container Runtime to start the application’s container.
About the Kube Proxy
Because an application deployment can consist of multiple application instances, a load balancer is required to expose them at a single IP address. The Kube Proxy, another controller running alongside the Kubelet, is responsible for setting up the load balancer.
Keeping the applications healthy
Once the application is up and running, the Kubelet keeps the application healthy by restarting it when it terminates. It also reports the status of the application by updating the object that represents the application instance. The other controllers monitor these objects and ensure that applications are moved to healthy nodes if their nodes fail.
Why use Kubernetes
The benefits of using Kubernetes
Self-service deployment of applications
Because Kubernetes presents all its worker nodes as a single deployment surface, it no longer matters which node you deploy your application to. This means that developers can now deploy applications on their own, even if they don’t know anything about the number of nodes or the characteristics of each node.
Reducing costs via better infrastructure utilization
If you don’t care which node your application lands on, it also means that it can be moved to any other node at any time without you having to worry about it. Kubernetes may need to do this to make room for a larger application that someone wants to deploy. This ability to move applications allows the applications to be packed tightly together so that the resources of the nodes can be utilized in the best possible way.
Finding optimal combinations can be challenging and time-consuming, especially when the number of all possible options is huge, such as when you have many application components and many server nodes on which they can be deployed. Computers can perform this task much better and faster than humans. Kubernetes does it very well. By combining different applications on the same machines, Kubernetes improves the utilization of your hardware infrastructure so you can run more applications on fewer servers.
Automatically adjusting to changing load
Using Kubernetes to manage your deployed applications also means that the operations team doesn’t have to constantly monitor the load of each application to respond to sudden load peaks. Kubernetes takes care of this also. It can monitor the resources consumed by each application and other metrics and adjust the number of running instances of each application to cope with increased load or resource usage.
When you run Kubernetes on cloud infrastructure, it can even increase the size of your cluster by provisioning additional nodes through the cloud provider’s API. This way, you never run out of space to run additional instances of your applications.
Kubernetes collects metrics (like CPU usage, memory, or custom application metrics) via the metrics-server or external monitoring systems (Prometheus, custom APIs). These metrics are used by autoscalers to decide when to add or remove Pods.
Horizontal Pod Autoscaler (HPA) is a core component within Kubernetes that automatically scales the number of Pods in a Deployment/ReplicaSet up or down based on thresholds (e.g., keep CPU < 70%).
Keeping applications running smoothly
Kubernetes is a self-healing system that can handle software errors and hardware failures.
Kubernetes makes every effort to ensure that your applications run smoothly. If your application crashes, Kubernetes will restart it automatically.
When a node fails, Kubernetes automatically moves applications to the remaining healthy nodes.
Simplifying application development
Kubernetes offers infrastructure-related services that would otherwise have to be implemented in your applications. This includes the discovery of services and/or peers in a distributed application, leader election, centralized application configuration and others.
How to install Kubernetes
Using a managed Kubernetes cluster in the cloud
Using managed Kubernetes services is ten times easier than managing it. Most major cloud providers now offer Kubernetes-as-a-Service. They take care of managing Kubernetes and its components while you simply use the Kubernetes API like any of the other APIs the cloud provider offers.
The top managed Kubernetes offerings include the following:
- Google Kubernetes Engine (GKE)
- Azure Kubernetes Service (AKS)
- Amazon Elastic Kubernetes Service (EKS)
- IBM Cloud Kubernetes Service
- Red Hat OpenShift Online and Dedicated
- VMware Cloud PKS
- Alibaba Cloud Container Service for Kubernetes (ACK)
Using the built-in Kubernetes cluster in Docker Desktop
If you use macOS or Windows, you’ve most likely installed Docker Desktop. It contains a single-node Kubernetes cluster that you can enable via its Settings dialog box. This may be the easiest way for you to start your Kubernetes journey.
Running a local cluster using Minikube
Another way to create a Kubernetes cluster is to use Minikube, a tool maintained by the Kubernetes community. The version of Kubernetes that Minikube deploys is usually more recent than the version deployed by Docker Desktop. The cluster consists of a single node and is suitable for both testing Kubernetes and developing applications locally.
If you configure Minikube to use a VM, you don’t need Docker, but you do need a hypervisor like VirtualBox. In the other case, you need Docker, but not the hypervisor.
Deploying a multi-node cluster from scratch
Until you get a deeper understanding of Kubernetes, I strongly recommend that you don’t try to install a multi-node cluster from scratch. If you are an experienced systems administrator, you may be able to do it without much pain and suffering, but most people may want to try one of the methods described in the previous sections first. Proper management of Kubernetes clusters is incredibly difficult. The installation alone is a task not to be underestimated.
When to use Kubernetes
When your system has more than twenty microservices
The first thing you need to think about is whether you need to automate the management of your applications at all. If your application is a large monolith, you definitely don’t need Kubernetes.
Even if you deploy microservices, using Kubernetes may not be the best option, especially if the number of your microservices is very small. It’s difficult to provide an exact number when the scales tip over, since other factors also influence the decision. But if your system consists of less than five microservices, throwing Kubernetes into the mix is probably not a good idea. If your system has more than twenty microservices, you will most likely benefit from the integration of Kubernetes. If the number of your microservices falls somewhere in between, other factors, such as the ones described next, should be considered.
When you prepared for increased costs in the interim
While Kubernetes reduces long-term operational costs, introducing Kubernetes in your organization initially involves increased costs for training, hiring new engineers, building and purchasing new tools and possibly additional hardware. Kubernetes requires additional computing resources in addition to the resources that the applications use.
More articles about Kubernetes
- Introduction to Kubernetes
- Getting Started with Kubernetes: Running Your First Application on Kubernetes
- Common Uses of Kubernetes
References
[1] Kubernetes in Action, 2nd Edition